![[鉴翎]中国鸟种识别模型训练-01数据工程](https://images.unsplash.com/photo-1713970294217-88b5a7084ec3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fGNoaW5hJTIwYmlyZHxlbnwwfHx8fDE3Nzc4MjMxNjB8MA&ixlib=rb-4.1.0&q=80&w=1920)
从多来源鸟图到可信训练语料
本篇面向所有做 ML 数据集构建的人。即使不关心鸟类识别,taxonomy、去重、split、防泄漏、source-shift 这些问题也很常见。
另见:训练路线与长尾采样见 02 模型训练篇;鸟框审计、拒识负样本和发布策略见 03 部署复盘篇。
在这个项目里,训练模型之前最重要的工作不是写网络结构,而是回答一个更基础的问题:我手里的每张图,究竟是不是我以为的那个物种?
这个问题听起来简单,实际很麻烦。不同来源有不同命名方式、不同标注质量、不同图片风格。有的来源按中文名建文件夹,有的按拉丁名,有的 label 来自搜索关键词,有的图甚至不是照片,而是音频波形、博物馆标签、标本说明页。
如果这些问题不先处理,模型训练只会把脏数据学得更熟。
一、数据源
原始数据不是一个单一数据集,而是多个来源的拼接。
| 来源 | 规模 | 主要用途 | 风险 |
|---|---|---|---|
| photos_v4_full | 约 181K | 中文名目录,主力数据 | 命名需统一 |
| gfib-images | 约 226K | 大规模补充 | 噪声较多 |
| Macaulay | 约 40K | eBird 高质量图片 | 许可需单独核查 |
| Semi-BD200 | 约 10K | 平衡数据 | 分辨率偏低 |
| ningxia | 约 12K | 含部件标注 | split 需保留 |
| birds525 | 约 19K | 公开分类数据 | 背景偏干净 |
| China-bird-YOLO | 约 29K | 含 bbox | label/bbox 需审 |
| birds-chenxian | 约 11K | 保护种补强 | 分布偏特定摄影师 |
| v4 API 补图 | 150,599 | 长尾与 extra 扩展 | 需做 bbox 与非照片过滤 |
原始数据合计约 567K 张,其中约 529K 张有 species 级标注。v4 又新增了 150,599 张去重后的补图。
设计原则很简单:
sources/只读,不直接修改。- 所有处理结果写到
taxonomy/、manifests/、quality/、corpus/。 - 删除优先写 action manifest,不做不可追溯的物理删除。
- 每张图始终保留
(source, src_path)作为身份。
二、taxonomy:先统一名字
鸟类数据里最容易出系统性错误的不是图片,而是名字。
同一种鸟可能有:
- 中文名
- 简繁写法
- 异体字
- 英文名
- 拉丁学名
- 旧学名
- 数据集内部 label
如果 taxonomy 不统一,同一个物种会被拆成多个类;如果异种被错误合并,训练标签就会被污染。
本项目以《中国鸟类名录 v12.0》作为 canonical 基础,共 1,516 种;同时使用中文名称对照表、eBird taxonomy、Avibase 等补充别名和 extra 类。
核心产物:
| 文件 | 内容 |
|---|---|
taxonomy/canonical.csv |
v12.0 canonical 物种 |
taxonomy/aliases.csv |
中文名、旧名、异名、拼音兜底 |
taxonomy/global_taxonomy.csv |
全球 taxonomy,供 extra 使用 |
匹配顺序:
- 学名精确匹配
- 中文名精确匹配
- 别名表匹配
- rapidfuzz 模糊匹配
- pypinyin 拼音兜底
_unmapped.csv人工处理
这里的 rapidfuzz 是模糊字符串匹配库,用来兜底处理轻微拼写差异;pypinyin 是中文转拼音库,用来处理文件名只有拼音或拼音近似的情况。
注意:taxonomy 错误比单张错图更危险,因为它会成批污染训练集。
三、从 flag 到 corpus
初版流水线如下:
sources/ 原始图片
↓
Stage 0 taxonomy 规范化
↓
Stage 1 各源映射
↓
Stage 2a 哈希去重
↓
Stage 2b DINOv3 特征去重
↓
Stage 3 鸟检测
↓
Stage 4 图像质量检查
↓
Stage 5 构建 corpus
↓
Stage 6 人工审核与决策
↓
Stage 7 构建训练 manifest
↓
Stage 8 observation cluster split
这里不建议一开始就 hard delete。更稳的方式是先写 quality_flags:
| Flag | 含义 |
|---|---|
corrupt |
图片无法打开 |
low_res |
分辨率过低 |
blur |
模糊 |
exposure |
曝光异常 |
no_bird |
未检测到鸟 |
hash_dup |
感知哈希重复 |
feature_dup |
DINOv3 特征近重复 |
cross_species_dup |
同图跨物种,强标错信号 |
这样阈值变化时可以重跑 corpus,而不是重新下载或手工恢复图片。
四、split:避免连拍泄漏
如果随机按图片切分,训练指标会虚高。因为同一次观察的连拍,可能一张进 train,一张进 test。模型不是学会了泛化,而是见过几乎一样的图。
本项目采用 observation cluster 策略:
python3 scripts/stage8_build_splits.py \
--cluster-thresh 0.90 --val-ratio 0.10 --test-ratio 0.05
策略:
- 已有官方 split 的来源保留原 split。
- 其它来源按物种分组。
- 用 DINOv3 CLS 特征聚类,cos > 0.90 视为同一 observation cluster。
- 同一个 cluster 只能进入同一个 split。
保留官方 split 不是因为它一定更干净,而是为了维持公开数据集原有评估边界,方便和外部结果对照;自建来源才统一进入 observation cluster 逻辑。
v2 split 结果:
| split | 图数 | 占比 |
|---|---|---|
| train | 382,589 | 84.24% |
| val | 44,959 | 9.90% |
| test | 26,627 | 5.86% |
这一步解决的是“同图/连拍泄漏”,但它不自动解决 source-shift。
五、source-shift:测试集是不是像真实用户照片
这是原稿里缺得比较明显的一块。
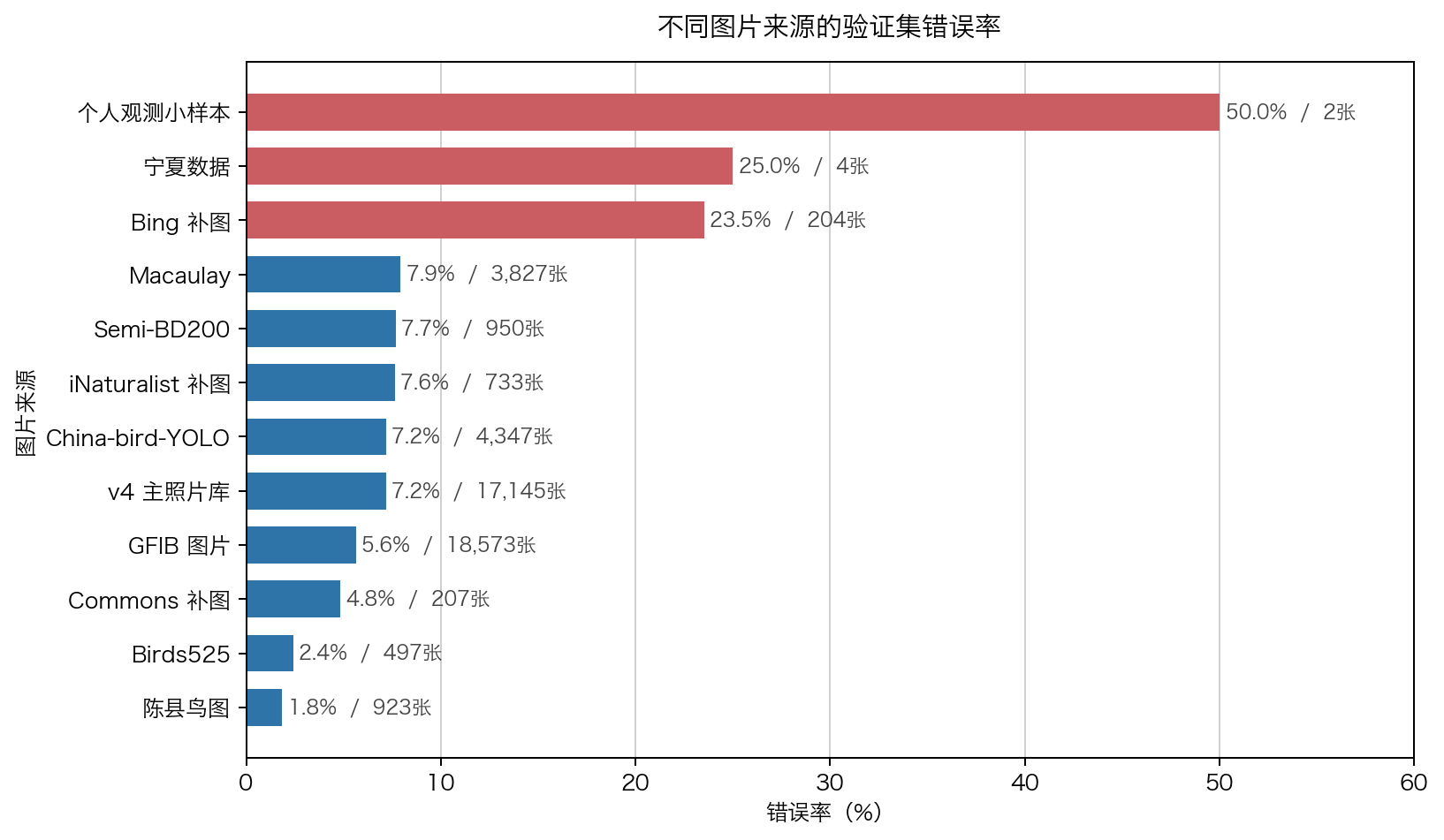
即使 split 没有泄漏,test set 也未必代表真实使用分布。比如 birds525 背景干净,Semi-BD200 分辨率偏低,Macaulay 质量较高,gfib 噪声更多。模型在不同来源上的错误率会不一样。
v3 LoRA 的 val source error breakdown:
| source | n_total | error_rate |
|---|---|---|
| birds-chenxian | 923 | 1.84% |
| birds525 | 497 | 2.41% |
| gfib-images | 18,573 | 5.64% |
| photos_v4_full | 17,145 | 7.17% |
| China-bird-YOLO | 4,347 | 7.18% |
| macaulay | 3,827 | 7.92% |
| aug_bing | 204 | 23.53% |
这说明两件事:
- 来源差异很大,整体 top-1 会掩盖 source-level 风险。
- 爬虫源如 aug_bing 应尽早进入 source blacklist 或低权重策略。
后续每次发布模型时,都应该把 per-source、长尾桶、真实用户照片子集和拒识误差一起报告。完整清单放在 03 部署复盘篇 的“发布前清单”里,避免每篇都散落一组未完成项。
六、数据源合规
另一个需要单独写清楚的是数据许可。
DINOv3 backbone 有 Meta 的 DINOv3 license;Macaulay / eBird / GBIF / iNaturalist / Wikimedia Commons / 各类公开图库也各自有使用条款。训练研究和模型发布不是同一件事,尤其是如果项目采用 GPL-3.0 或计划公开分发,更不能把所有来源一概当作可再分发资产。
本文建议把合规分成三层:
| 层级 | 处理 |
|---|---|
| 模型权重 | 明确 DINOv3 license 与部署限制 |
| 图片数据 | 不随仓库分发原图,保留来源与许可字段 |
| 训练产物 | 发布前逐源核查是否允许训练后模型发布 |
如果要正式开源,应至少提供:
- 数据来源清单
- 不包含原图的 manifest
- 每个来源的 license / terms 说明
- 可删除指定来源重训的脚本路径
七、非照片样本

非照片样本不只是“脏图”,它们后来也变成了 reject head 的强负样本来源。具体构造和权重设计见 03 部署复盘篇。
小结
这一阶段的核心不是“筛出更多图片”,而是把每张图片放到一个可追溯、可重跑、可解释的位置上。只有当 taxonomy、split、去重、来源质量和合规边界都清楚以后,后面的模型指标才有意义。
下一篇讲训练:为什么从 YOLO baseline 切到 DINOv3,为什么 frozen feature 是一个很好的中间层,以及那些把模型直接带歪的超参。
wlfcss原创,转载请注明来源

![[鉴翎]中国鸟种识别模型训练-03部署复盘](https://images.unsplash.com/photo-1713970294217-88b5a7084ec3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fGNoaW5hJTIwYmlyZHxlbnwwfHx8fDE3Nzc4MjMxNjB8MA&ixlib=rb-4.1.0&q=80&w=1140)