![[鉴翎]中国鸟种识别模型训练-02模型训练](https://images.unsplash.com/photo-1713970294217-88b5a7084ec3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fGNoaW5hJTIwYmlyZHxlbnwwfHx8fDE3Nzc4MjMxNjB8MA&ixlib=rb-4.1.0&q=80&w=1920)
从 YOLO baseline 到 DINOv3 LoRA
本篇面向关心训练路线和调参取舍的读者。重点不是把所有 run 堆出来,而是解释每一步为什么做、哪里翻车、最后留下了什么经验。
另见:训练数据、taxonomy 与 split 见 01 数据工程篇;鸟框审计、reject head 负样本和桌面端部署见 03 部署复盘篇。
数据清理到一定程度后,才轮到模型训练。
这个项目的训练路线大致经历了三步:
- YOLO-cls baseline:验证传统分类路线的上限。
- DINOv3 frozen feature:快速建立强 baseline。
- DINOv3 LoRA:在清洗数据上进一步提升上限,并加入 reject head。
一、为什么选 DINOv3
早期可以选的 backbone 很多:CLIP、SigLIP、EVA-02、ConvNeXt、YOLO-cls、DINOv3。这里没有做一轮完整的公开模型横向评测,所以不能写成“DINOv3 全面最优”。更准确的说法是:在本项目已有数据和工程条件下,DINOv3 是最先跑出强 baseline 且训练路径最清晰的方案。
选择 DINOv3 的主要原因:
- 自监督视觉表征在细粒度分类上通常比通用图文 embedding 更适合作为 frozen feature。
- ViT token 结构方便使用
CLS + mean patch这类 pooled feature。 - frozen backbone 可以先抽特征,再用很低成本扫 head、loss、sampler 和 seed。
- DINOv3 ViT-L 在本项目上很快超过 YOLO baseline。
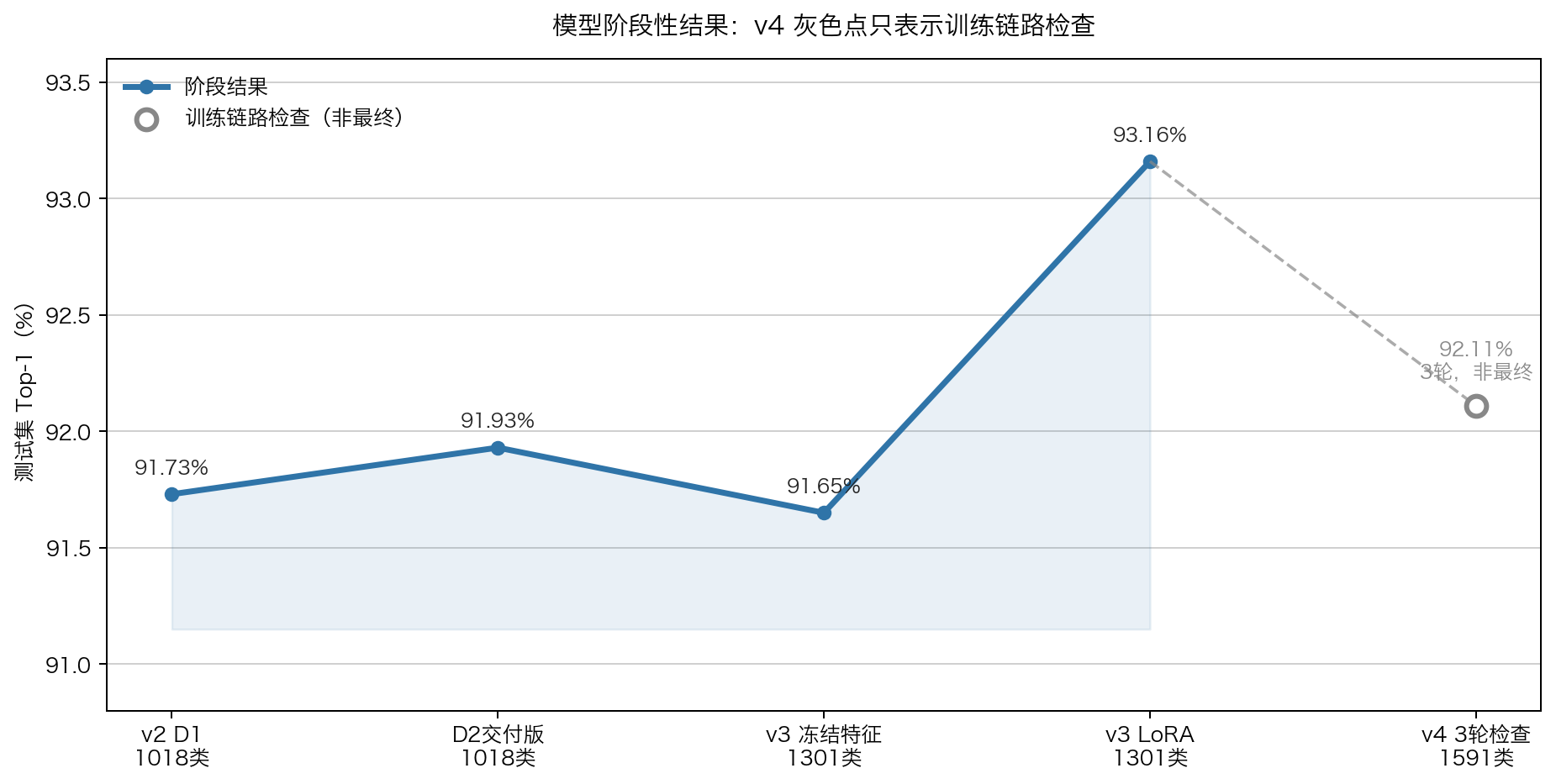
YOLO26m baseline 约 86.80%,而 v2 D1 的 DINOv3 frozen 4-seed ensemble 达到 91.73%,这足够说明路线值得继续。
注意:CLIP / SigLIP / EVA-02 仍然值得后续补一个小规模对照,尤其是 reject / unknown 场景可能有互补价值。
二、Frozen feature baseline
第一阶段不直接 fine-tune backbone,而是冻结 DINOv3 ViT-L/16 抽特征。
DINOv3 输出 token 后,取:
feature = CLS token ⊕ mean(patch tokens)
这里的 register tokens 指 DINOv3 中额外插入的全局 token,它们不对应图像 patch。计算 patch mean 时要跳过这些 token,否则特征会混入非 patch 信息。本项目 ViT-L 有 4 个 register tokens。
分类头训练:
python3 scripts/stage10_train.py \
--mode cached --epochs 20 --batch-size 256 --num-workers 4 \
--lr 1e-3 --dropout 0.1 --sampler-beta 0.999 \
--run-name phase1_baseline
主要配置:
| 项 | 配置 |
|---|---|
| Backbone | DINOv3 ViT-L/16 frozen |
| Feature | CLS + mean patch, 2048-d |
| Head | LayerNorm + Dropout + Linear |
| Loss | Balanced Softmax |
| Aux heads | order / family / genus |
| Sampler | effective-number, β=0.999 |
| Optimizer | AdamW |
Balanced Softmax 是一种长尾分类损失,会把类频次先验纳入 softmax,避免模型过度偏向样本量大的头部类。
effective-number sampler 则根据每个类别的有效样本数调整采样权重。β 越接近 1,长尾类权重越高。
三、第一次翻车:长尾采样过猛
训练中最典型的翻车是 β=0.9999。
动机很合理:想给长尾类更多采样权重。问题是 β=0.9999 会让 tail/head 采样权重比过大,模型几乎被尾部类牵着走。
结果:
| 配置 | 结果 |
|---|---|
| β=0.999 | epoch 8 val top-1 82.4%,best epoch 11 val top-1 90.6%,test top-1 89.92% |
| β=0.9999 | peak epoch 7 val top-1 4.94%,final epoch 12 降到 3.99% |
这件事的教训是:长尾不是越补越好。Balanced Softmax 已经做过一层频次校准,再叠加过强的 sampler,会让模型在推理时偏离真实分布。
这张训练曲线暂时不能完整复原:phase1_v2 (β=0.9999) 的 run 目录当时已经按日志处置删除,只剩下 peak epoch 7 = 4.94% 和 final epoch 12 = 3.99% 两个关键点。为了不伪造曲线,这里只写可追溯数字;如果能从终端日志或备份里找回逐 epoch history,再把它和 β=0.999 的正常 run 放在同一张图里。
另外几组失败方向汇总在第七节。
最后采用的策略是:
- 超参锁死。
- 只做 seed diversity。
- 新超参先小样本 smoke,再放全量。
四、D1 结果
D1 是我在训练日志里对第一轮 frozen-feature baseline 的内部命名。它的目的不是冲最终上限,而是验证 DINOv3 特征、长尾损失、采样器和 split 是否可靠。
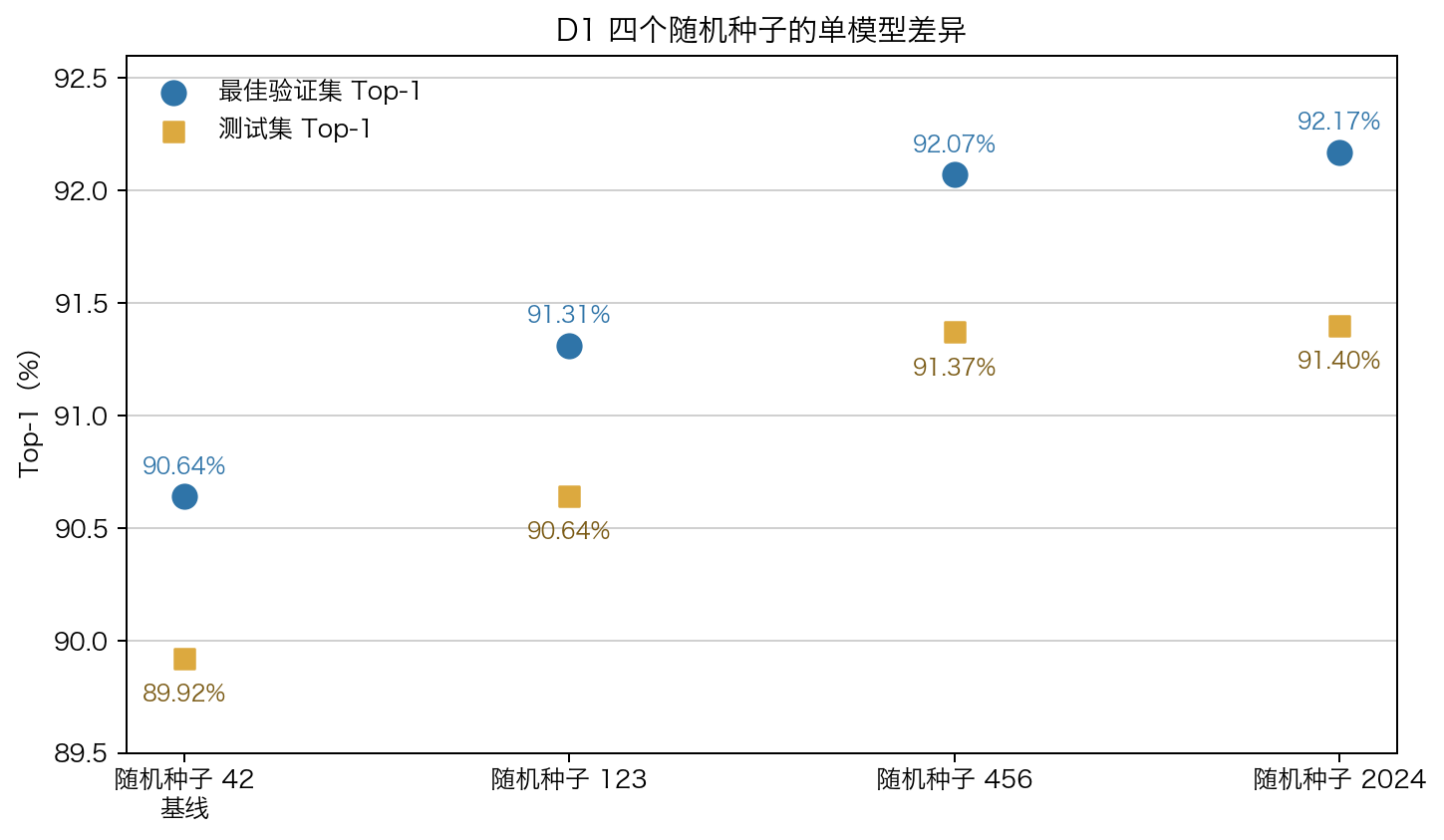
4 个 seed 的 frozen head 结果:
| 模型 | test top-1 | top-5 | macro |
|---|---|---|---|
| phase1_baseline | 89.92% | 93.40% | 88.60% |
| phase1_seed123 | 90.64% | 94.48% | 89.23% |
| phase1_seed456 | 91.37% | 96.24% | 89.93% |
| phase1_seed2024 | 91.40% | 96.43% | 90.00% |
| 4-model ensemble | 91.73% | 95.52% | 90.24% |
这里也试过 τ-norm。τ-norm 是一种对分类器权重范数做校准的后处理,常用于长尾分类。但在本项目中,最佳 τ 全部为 0。原因大概率是 Balanced Softmax 已经做了校准,再做 τ-norm 等于二次修正。
五、v3 扩类与 ensemble
v3 将物种从 1,018 扩到 1,301,corpus 规模从 v2 的 454K 扩到 481K。这里的 454K 是 train / val / test 合计;如果只看 v2 train split,是 382,589 张。
| 组合 | 模型数 | test top-1 | top-5 | macro |
|---|---|---|---|---|
| ViT-L 8×480 | 8 | 91.50% | 96.98% | 91.32% |
| ViT-L multi-scale | 16 | 91.55% | 97.15% | 91.32% |
| ViT-L multi-scale + ViT-B | 24 | 91.65% | 97.16% | 91.43% |
需要注意的是,v3 的 91.65% 低于 v2 的 91.73%。所以严谨写法不是“扩类后保持指标”,而是“增加 283 个类后整体 top-1 仅下降 0.08pp,说明扩类没有导致明显崩溃”。更严格的对比应补同一 1,018 类子集上的指标。
ConvNeXt-L 被淘汰:
| 模型 | 结论 |
|---|---|
| ConvNeXt-L 480 | val top-1 约 82-83% |
| ConvNeXt-L 224 | 仍约 82-83% |
| 加入 ensemble | 反而略降 |
原因可能不是 ConvNeXt 一定差,而是当前 cached feature + head-only 训练范式更适合 ViT-L。ConvNet 可能更依赖在线图像增强,抽成固定 feature 后损失了训练空间。
六、LoRA 微调
Frozen backbone 快而稳,但上限有限。下一步做 LoRA。
LoRA 是一种参数高效微调方法,不更新整个 backbone,而是在注意力层的 q/v 投影权重上加一对低秩可训练矩阵。这样训练参数少、显存压力低,也更适合大模型微调。
本项目 LoRA 配置:
| 项 | 配置 |
|---|---|
| target | q / v projection |
| r | 8 |
| alpha | 16 |
| dropout | 0.05 |
| lora lr | 1e-4 |
| head lr | 1e-3 |
| weight decay | 0.1 |
| epochs | 30 |
为什么只做 q/v:
- 多数 ViT LoRA 实践中 q/v 是性价比较高的插入点。
- k/o 也可能有收益,但会增加参数和不稳定性。
- 当前 r=8、q/v 是参考文献和工程常用配置后选定,并未做完整 r/k/o sweep。
这一点在正式文章里应诚实说明:它是一个合理工程选择,不是严格消融结论。
v3 LoRA @224 结果:
| 指标 | 值 |
|---|---|
| best val top-1 | 93.44% |
| test top-1 | 93.16% |
| test top-5 | 98.27% |
相对 v3 frozen 91.65%,LoRA 提升约 1.51pp;相对 v2 D1 91.73%,提升约 1.43pp。
只报这个提升还不够。真正值得补的是 per-class delta:哪些物种提升最大,头部类和长尾类分别提升多少,错误是否从“跨科错”变成“近缘相似种错”,以及 LoRA 是否改善低质量来源。这个统计已并入部署篇末尾的发布前清单。
七、不工作的几个方向
把失败尝试分散写在各节里,读起来容易被成功路线盖过去。真正有复用价值的反而是这些“不工作”的方向:
| 尝试 | 结果 | 可能原因 |
|---|---|---|
| β=0.9999 长尾采样 | peak val top-1 只有 4.94% | sampler 和 Balanced Softmax 同时过度补偿长尾 |
| 降 lr + 加 dropout | 12 epoch 几乎学不起来,val macro 约 0.00-0.23% | 原始 logits 太平,推理时几乎全选 tail 类 |
| ConvNeXt-L cached feature | 480 / 224 都只有约 82-83% val top-1,加入 ensemble 反而略降 | 当前 head-only 范式更适合 ViT frozen feature;ConvNet 可能更依赖在线增强 |
| τ-norm | 最佳 τ 全部为 0 | Balanced Softmax 已经做过频次校准,再叠 τ-norm 等于二次修正 |
这几个失败有一个共同点:它们看起来都是“更稳”或“更平衡”,但在这个数据分布下会把模型推离真实测试分布。
八、输入分辨率不是越大越好
用户反问过一个很关键的问题:480 重建会不会只是把小图放大?
查 crop side 分布后发现:
| crop side | 占比 |
|---|---|
| <224px | 19.5% |
| <320px | 37.9% |
| <480px | 58.5% |
| ≥480px | 41.5% |
如果直接训练 480,超过一半样本都在做插值放大。模型看到的不是更多细节,而是更大的伪细节。
因此 v4 改为 384 输入,并过滤 crop side 太小的样本。这不是“向低分辨率妥协”,而是基于真实数据分布的折中。
九、v4 当前训练
v3 LoRA 完成后,下一个目标不是继续压榨 top-1,而是让模型能输出“无法识别”。原因详见部署篇:对观鸟用户来说,错识比拒识更伤体验。这就引出了 v4 的双头设计:species head 继续学已知鸟种分类,新增 reject head 学“这张图是否应该进入物种识别”。
v4 训练 manifest:
| 项 | 数量 |
|---|---|
| 入训总行数 | 588,838 |
| 正样本 | 562,371 |
| reject negative | 26,467 |
| 入训类 | 1,591 |
| 被阻断类 | 18 |
| bbox 缺失 | 0 |
这里的类数需要单独解释:v4 目标目录是 1,612 类,但训练 manifest admission 之后,实际进入 class_map 的是 1,591 类;18 个 v12 类因为无法同时满足 train ≥50、val ≥5 被列入 blocker;另外 3 个 v12 类在这一轮没有可用正样本,未进入 class_map / blocker,分别是细纹苇莺、中华长尾雀、西南灰眉岩鹀。也就是说,1,612 是 collection target,1,591 才是本轮实际入训类数。
reject negative 的来源和 strong / weak 权重不在训练篇展开,详见 03 部署复盘篇。
v4 LoRA + reject head:
| 项 | 配置 |
|---|---|
| 输入 | 384 × 384 |
| Backbone | DINOv3 ViT-L/16 |
| LoRA | q/v, r=8, alpha=16 |
| Species head | MLP-2048 |
| Reject head | Binary reject head |
| Batch | 40 positive + 8 reject negative |
| Loss | capped BalancedSoftmax + BCE reject |
3 epoch smoke:
| Epoch | val top-1 | top-5 | macro | reject AUC |
|---|---|---|---|---|
| 1 | 90.50% | 97.58% | 87.24% | 0.906 |
| 2 | 91.96% | 97.94% | 90.84% | 0.922 |
| 3 | 92.31% | 97.99% | 91.79% | 0.926 |
smoke final test top-1 为 92.11%,top-5 为 98.08%,reject AUC 为 0.920。这里的 smoke 指“全量 manifest + 缩短到 3 epoch 的 dev run”,用途是确认训练链路、拒识头和指标量级是否正常,不把它当最终模型选型。正式主训练应继续用 val 做选择,test 只保留为一次性报告口径,避免反复暴露 test set。
小结
训练阶段最大的经验不是某个神奇超参,而是:先用 frozen feature 建立可靠、快速、可回滚的 baseline,再决定是否上 LoRA。对这种多来源长尾细粒度数据,盲目端到端训练很容易把数据问题伪装成模型问题。
下一篇讲部署和复盘:为什么 bbox 比想象中更关键,reject negative 从哪里来,以及一个模型要变成产品还差哪些工程环节。
wlfcss原创,转载请注明来源

![[鉴翎]中国鸟种识别模型训练-03部署复盘](https://images.unsplash.com/photo-1713970294217-88b5a7084ec3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fGNoaW5hJTIwYmlyZHxlbnwwfHx8fDE3Nzc4MjMxNjB8MA&ixlib=rb-4.1.0&q=80&w=1140)