![[鉴翎]中国鸟种识别模型训练-导论](https://images.unsplash.com/photo-1713970294217-88b5a7084ec3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fGNoaW5hJTIwYmlyZHxlbnwwfHx8fDE3Nzc4MjMxNjB8MA&ixlib=rb-4.1.0&q=80&w=1920)
让我决定做鸟类识别模型的,不是某个排行榜指标,而是一次很普通的使用场景:照片里确实有鸟,模型也很自信,但名字错得离谱。更麻烦的是,它不是随机错,而是在相似种、远景小目标、裁切漂移、背景干扰这些场景里非常自信的出错,这几乎不可避免,全球有1万余种鸟类,一个覆盖全球鸟类(比如懂鸟)的识别模型,如果不结合 GIS等地理信息在识别精度上会惨不忍睹。
这类错误对观鸟摄影爱好者很糟糕。拍完一批照片后,用户并不是想研究模型为什么错,只是希望它至少别把一张明显信息不足的图硬说成某个具体物种。对这个产品来说,拒识要比错识更重要。
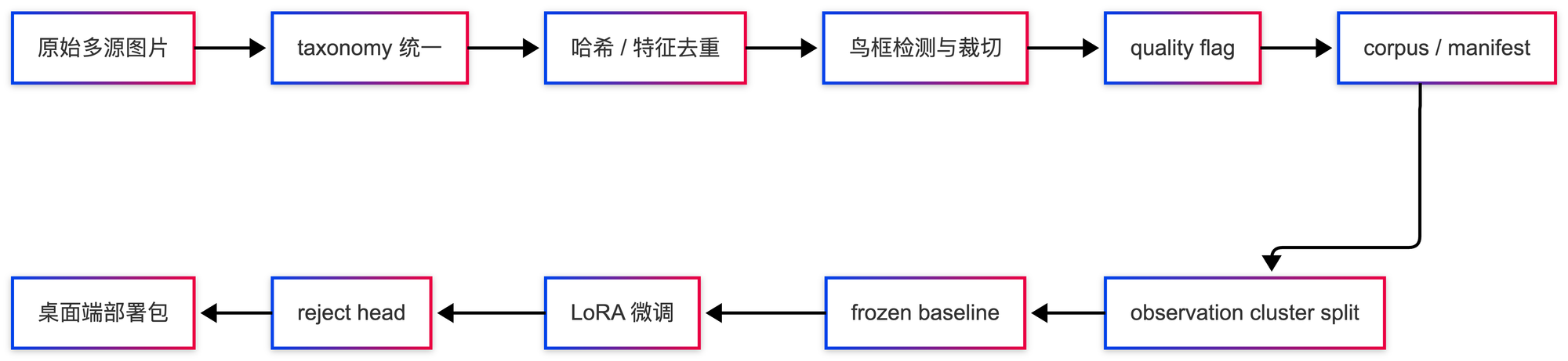
于是这个项目从“训练一个分类模型”,逐渐变成了一整套数据与模型工程:先统一物种名录,再清洗多来源图片,再处理 bbox 裁切,再解决长尾采样,最后才是 DINOv3 训练。
目标
一个面向中国观鸟摄影爱好者的鸟类识别模型:
- 输入单张鸟类照片
- 输出 Top-K 物种预测
- 同时返回中文名、学名、英文名、科属、IUCN、保护等级
- 对无鸟、裁切失败、置信度不足的图片尽量拒识
它不是科研监测系统,也不试图识别世界所有鸟类。第一阶段以《中国鸟类名录 v12.0》的 1,516 种为基础,后续又加入 96 个中国真实场景中常见的观赏鸟、圈养鸟和动物园鸟类,目标目录扩大到 1,612 类。
为什么不能只训模型
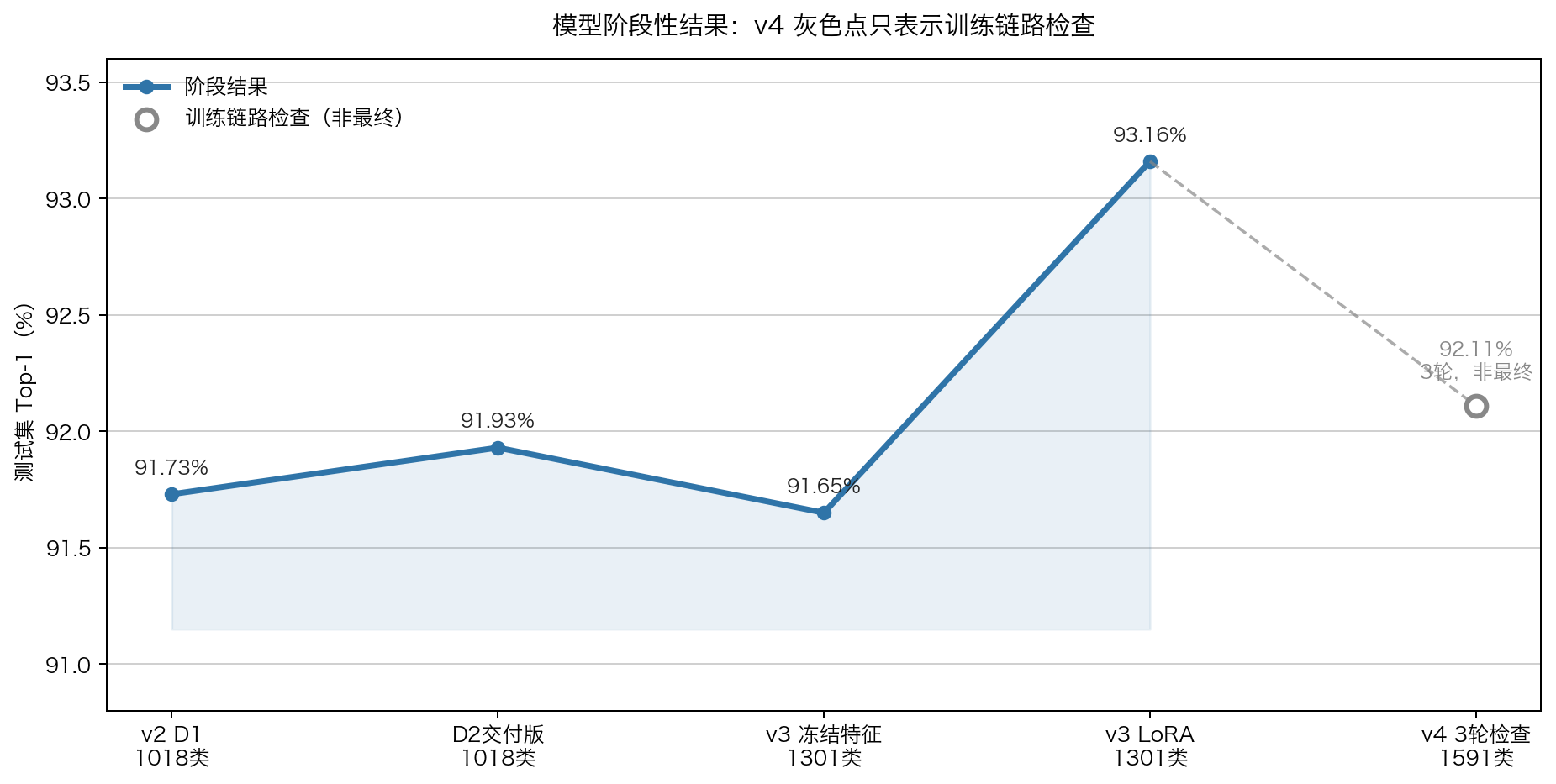
如果只看模型,DINOv3 已经足够强。Frozen backbone 加一个分类头,v2 的 1,018 类模型就能做到 91.73% test top-1;v3 扩到 1,301 类后,24 ckpt ensemble 仍然有 91.65%;v3 LoRA @224 进一步到 93.16%。
但这些数字背后有一堆更重要的问题:
- 同一种鸟在不同数据源里可能有不同中文名、旧学名和别名
- 同一次观察的连拍如果同时进入 train 和 test,指标会虚高
- bbox 裁歪了,模型看到的就不是鸟
- 常见鸟有几千张图,稀有鸟可能只有几十张
- Qwen 返回的 bbox 是
[0,1000]归一化坐标,不是像素 - 过度长尾采样会把模型带歪
- 一些公开数据源背景太干净,未必代表真实用户照片
- 训练数据许可和模型权重许可不能混为一谈
所以这个系列会分成三篇:
- 数据工程篇:从多来源图片到可信训练语料,重点讲 taxonomy、去重、split、合规和 source-shift。
- 模型训练篇:从 YOLO baseline 到 DINOv3 frozen feature,再到 LoRA,重点讲训练路线、长尾、分辨率和翻车案例。
- 部署复盘篇:从 bbox 裁切到 reject head,重点讲 Qwen/PlumeLens 审计、模型包、延迟、负样本和产品策略。
整体流程大致是这样:
版本命名
项目里同时出现 v1 / v2 / D1 / D2 / v3 / v4,容易绕。可以先按这个表理解:
| 阶段 | 类数 | 关键变化 |
|---|---|---|
| v1 / YOLO baseline | - | 路线验证,top-1 约 86.80%,未作为最终路线 |
| v2 D1 | 1,018 | 首版 DINOv3 frozen baseline,验证特征、采样器和 split |
| v2 D2 | 1,018 | 多尺度交付版,提升部署口径下的稳定性 |
| v3 frozen | 1,301 | 扩类后做 24 ckpt ensemble |
| v3 LoRA | 1,301 | 单 LoRA 模型反超 frozen ensemble |
| v4 训练中 | 1,591 | LoRA @384 + reject head,主跑仍在进行 |
当前结果
下表只放已经可以作为阶段结果比较的模型。v4 的 3 轮训练链路检查只用于确认训练流程和 reject head 是否正常,不代表最终 v4 指标,细节放在 02 模型训练篇。
| 阶段 | 类数 | 数据规模 | 模型 | test top-1 |
|---|---|---|---|---|
| v2 D1 | 1,018 | 454K | Frozen ViT-L 4-seed ensemble | 91.73% |
| D2 delivery | 1,018 | 454K | 多尺度 ensemble | 91.93% |
| v3 frozen | 1,301 | 481K | ViT-L + ViT-B 24-ckpt ensemble | 91.65% |
| v3 LoRA | 1,301 | 481K | ViT-L LoRA @224 | 93.16% |
这里有一个需要提前说明的地方:v3 的 91.65% 低于 v2 的 91.73%,不能写成“性能保持不变”。更准确的说法是:类别数从 1,018 增加到 1,301 后,整体 top-1 只下降 0.08pp,说明扩类后没有明显崩掉。最严谨的对比口径,是在同一 1,018 类子集上再算一次指标。
后续
这个系列不是一个专业的“炼丹指南”,而是记录一个细粒度识别模型如何从混乱数据里长出来。真正值得写下来的,往往不是成功的那一行指标,而是那些把模型带歪的地方。三篇主体写完后,如果 v4 主跑和真实用户照片基准完成,我会再补一篇发布复盘。
TODO:训练资料及相关脚本后续将发布在Github。
wlfcss原创,转载请注明来源

![[鉴翎]中国鸟种识别模型训练-03部署复盘](https://images.unsplash.com/photo-1713970294217-88b5a7084ec3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fGNoaW5hJTIwYmlyZHxlbnwwfHx8fDE3Nzc4MjMxNjB8MA&ixlib=rb-4.1.0&q=80&w=1140)