![[鉴翎]中国鸟种识别模型训练-03部署复盘](https://images.unsplash.com/photo-1713970294217-88b5a7084ec3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fGNoaW5hJTIwYmlyZHxlbnwwfHx8fDE3Nzc4MjMxNjB8MA&ixlib=rb-4.1.0&q=80&w=1920)
bbox、reject head 与那些把模型带歪的细节
本篇面向产品工程和模型落地读者。重点是模型训练完成后,如何让它在真实用户图片里少错、敢拒、可部署。
另见:数据源、split 和 source-shift 见 01 数据工程篇;DINOv3 frozen / LoRA 训练路线见 02 模型训练篇。
鸟类识别模型真正进入产品时,问题不再只是 top-1。
用户不会关心你是 ViT-L 还是 ConvNeXt,也不会关心 Balanced Softmax。他只会看到:这张图有没有识别对?不确定的时候有没有乱猜?上传一张照片要等多久?安装包会不会太大?
所以部署阶段的关键问题是:
- 鸟有没有被裁对?
- 信息不足时能不能拒识?
- 模型包和延迟能不能被桌面端接受?
- 数据和权重许可是否允许发布?
一、bbox 比想象中更重要
如果鸟占整图很小,直接整图分类会让模型看到大量背景。对细粒度识别来说,这很危险。模型需要看到喙、眼圈、头纹、翼斑、尾羽,而不是水面、枝叶和天空。
推理链路:
原图
↓
EXIF 正向化
↓
鸟 bbox 检测
↓
扩展 15% margin
↓
方形裁切
↓
DINOv3 分类
曾经踩过一个典型坑:Qwen 返回 bbox 是 [0,1000] 归一化坐标,不是像素坐标。
正确换算:
pixel_x = qwen_x / 1000 * image_width
pixel_y = qwen_y / 1000 * image_height
如果把它当像素读,裁切框会系统性偏移。这个错误不会报异常,但会把模型稳定喂错区域。

二、Qwen vs PlumeLens
项目里用过几类裁切器:
| 方案 | 特点 | 问题 |
|---|---|---|
| Qwen3-VL / Qwen3.5-4b | 慢,但 VLM 判断更准 | 本地部署重,数秒级 |
| PlumeLens detector | 快,适合产品 | 小目标会漂移 |
| COCO YOLO | 可 fallback | 容易误检非鸟 |
| 无裁切 | 最简单 | 远景与复杂背景掉点明显 |
v4 新补图 Qwen bbox 最终结果:
| 状态 | 数量 |
|---|---|
| ok | 147,862 |
| no_bbox | 2,737 |
| 合计 | 150,599 |
后续又用 PlumeLens detector 做独立审计,比较 Qwen bbox 和 PlumeLens bbox。
规则:
- 人工决策最高优先级。
- 未审样本如有 PlumeLens bbox,默认改用 PlumeLens bbox。
- 未审样本如无 PlumeLens bbox,且丢弃后物种仍 ≥80,则保守自动丢弃。
- 会导致物种低于 80 的样本进入人工复核。
v4 审计结果:
| 项 | 数量 |
|---|---|
| 比较范围 | 147,691 |
| review rows | 17,820 |
| 人工决策 | 1,724 |
| 自动改用 PlumeLens bbox | 11,896 |
| 自动保守废弃 | 4,200 |
| 最终需人工复核 | 0 |
老 v3 图也做了同样审计:
| 项 | 数量 |
|---|---|
| 比较范围 | 420,559 |
| review rows | 69,701 |
| 人工决策 | 944 |
| 自动改用 PlumeLens bbox | 43,263 |
| 自动保守废弃 | 25,494 |
| 最终需人工复核 | 0 |
单纯表格很难让人理解“裁切漂移”到底有多严重,Qwen vs PlumeLens 的鸟框对比图会更直观。
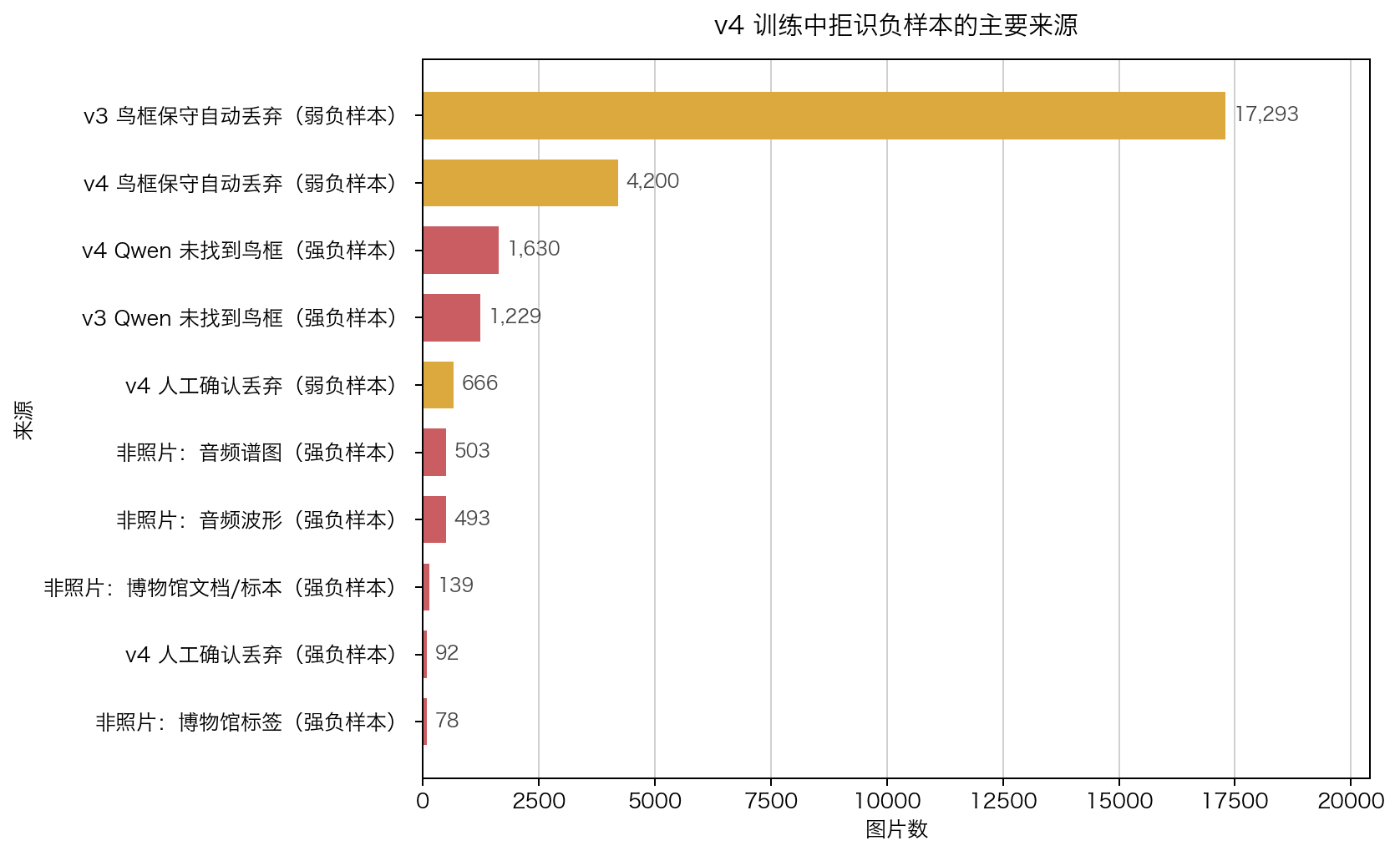
三、reject head 的负样本从哪里来
原稿没有解释 reject negative,这是复现读者会问的。
v4 训练 manifest 中有 26,467 张 reject negative。它们不是随便找的背景图,而是来自真实清洗流程中“模型很可能遇到、但不应该识别成已知物种”的样本。
负样本来源:
| reject_reason | strength | 数量 |
|---|---|---|
| v3_bbox_auto_drop_conservative_safe_ge80 | weak | 17,293 |
| v4_bbox_auto_drop_conservative_safe_ge80 | weak | 4,200 |
| v4_qwen_no_bbox | strong | 1,630 |
| v3_qwen_no_bbox | strong | 1,229 |
| v4_bbox_manual_drop_confirmed | weak | 666 |
| nonphoto_audio_spectrogram_image | strong | 503 |
| nonphoto_audio_waveform_image | strong | 493 |
| nonphoto_museum_document_or_specimen | strong | 139 |
| nonphoto_museum_label_photo | strong | 78 |
| nonphoto_museum_specimen_or_label | strong | 47 |
| nonphoto_qwen_fullframe_false_positive_no_animal | strong | 18 |
| hho_drop_no_animal | strong | 8 |
其中 weak negative 权重为 0.3,strong negative 权重为 1.0。
reject head 训练时默认 feat.detach(),也就是拒识损失不反向更新 LoRA backbone,避免它为了区分非鸟/坏图而破坏物种识别表征。
这是一个保守设计:
- species head 负责“已知鸟种里是哪一个”
- reject head 负责“这张图像不像应该进入物种识别”
- reject 不直接牵动 backbone,降低对主任务的干扰
这部分的发布前评估集中放到文末清单:已知鸟误拒、非鸟误接受、阈值标定和 UI 文案需要一起看,单独优化一个 AUC 不够。
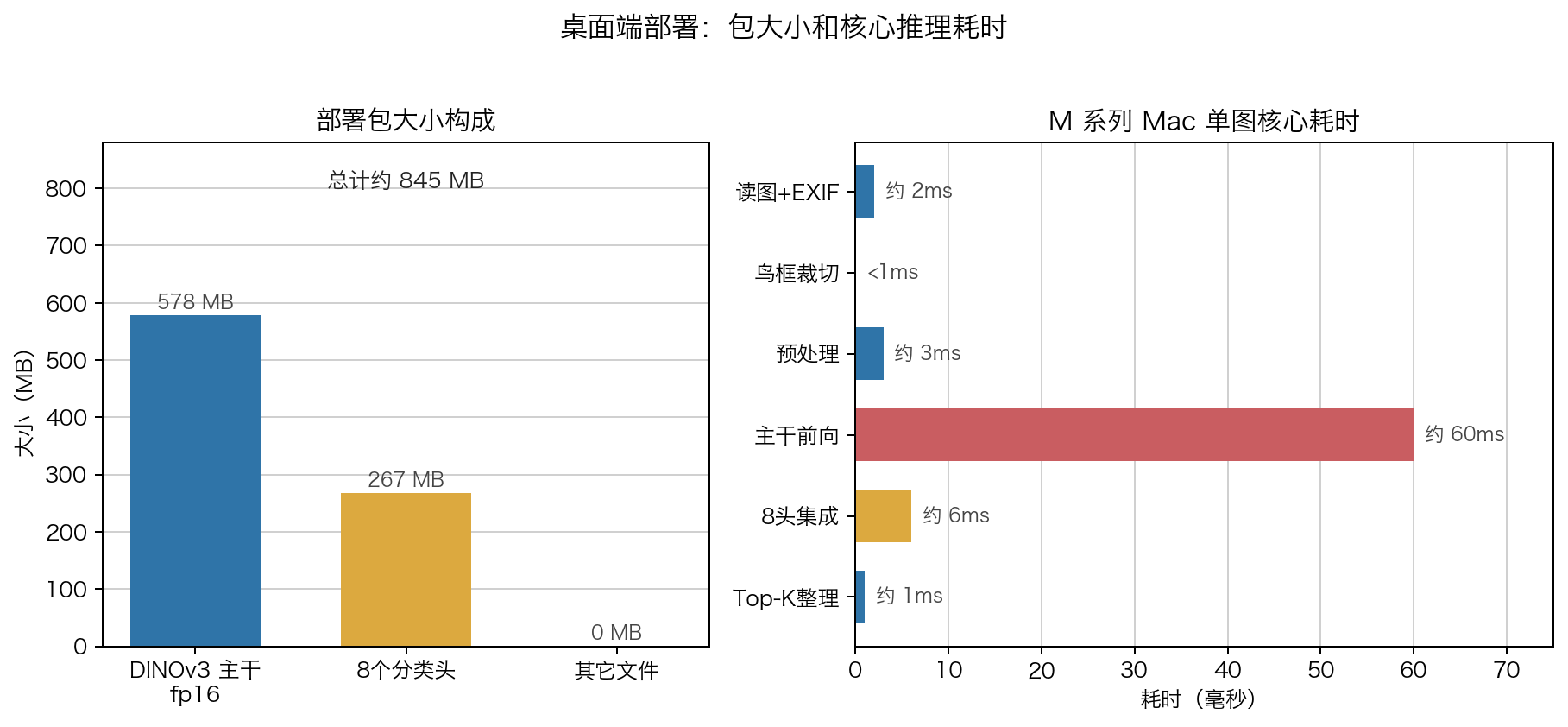
四、部署包
当前 v3 部署包:
deploy_v3/
├── backbone/ # DINOv3 ViT-L/16 fp16
├── heads/ # 多 seed head ckpt
├── canonical_extended.parquet # 物种元数据
└── README.md
包大小约 845MB:
| 部分 | 大小 |
|---|---|
| backbone fp16 | 578MB |
| 8 heads | 267MB |
| metadata | <1MB |
推理示例:
from bird_predictor import BirdPredictor
predictor = BirdPredictor("path/to/deploy_v3")
result = predictor.predict("photo.jpg", top_k=5)
print(result["topk"][0])
M 系列 Mac 核心推理耗时:
| 阶段 | 耗时 |
|---|---|
| Image load + EXIF | 约 2ms |
| Preprocess | 约 3ms |
| Backbone forward @480 | 约 60ms |
| 8-head ensemble | 约 6ms |
| Top-K formatting | 约 1ms |
| 合计 | 约 72ms |
跨平台预期:
| 平台 | Backbone forward |
|---|---|
| Apple Silicon MPS | 约 60ms |
| NVIDIA CUDA | 约 10-20ms |
| CPU | 约 500ms,不推荐 |
MPS 是 Apple Silicon 上的 GPU 计算后端,可以理解成 macOS 侧的 CUDA 替代路径。
部署指标里必须把两个工程点单独拆开:
- 首启动延迟:模型加载和权重搬到设备的耗时应单独测量,不能混入单图推理延迟。
- 低内存退化策略:低内存机器可减少 head 数量,例如 8 head 降到 4 head,包大小和内存下降,精度损失约 0.05-0.1pp。
五、量化与设备策略
部署目录里的 fp16 指磁盘上的半精度权重格式;推理时按设备走不同计算精度:Apple Silicon / MPS 优先用 bf16 避开 RoPE 数值问题,CUDA 可按显卡能力用 bf16 或 fp16,CPU fallback 使用 fp32。
已验证:
| 项 | 结果 |
|---|---|
| bf16 vs fp32 cosine similarity | 0.999999 |
| max abs feature diff | 0.003 |
| test predictions | 一致 |
量化还有继续空间:
| 方案 | 价值 | 风险 |
|---|---|---|
| head int8 | 简单,收益有限 | 几乎无风险 |
| backbone int8 | 包大小和内存显著下降 | 需重测细粒度精度 |
| 4-head ensemble | 直接减小 head 包 | 轻微掉点 |
| LoRA merge / adapter | v4 需要重新设计部署包 | 需验证加载路径 |
六、Hybrid 方案
Hybrid 方案目前是 v4 主跑完成后的候选方向,尚未实施。这里给一个更清楚的定义,作为后续 ablation 备选。
可能的 hybrid 不是“把所有模型都堆上去”,而是:
- LoRA 单模型作为主力:速度快,精度高。
- Frozen ensemble 作为 fallback / referee:在 LoRA 低置信、reject 边界、相似种混淆时参与投票。
- 只在疑难样本上启用重模型:避免每张图都付出 ensemble 成本。
这样可以兼顾:
- 常规图片低延迟
- 疑难图片更稳
- 发布包可按设备能力裁剪
但 hybrid 的代价是 UI 和置信度策略复杂很多,需要定义:
- 两个模型冲突时听谁的
- top-1 低置信但 top-5 正确时如何展示
- reject head 与 ensemble disagreement 如何共同决定 unknown
这里的“低置信”不能只看一个 top-1 概率。更稳的触发条件应该是一个组合规则:top-1 概率低于校准阈值、top-1/top-2 margin 过小、reject score 落在灰区,或 top-5 命中了高频混淆物种对。阈值不建议在文章里拍脑袋给死数,应在 val + 真实用户照片小集上标定;产品上可以先定义为“任一条件命中则交给 frozen ensemble 复核”。
七、合规与发布边界
模型发布前必须重新看数据源许可。
需要区分:
| 对象 | 风险 |
|---|---|
| DINOv3 backbone | Meta DINOv3 license |
| Macaulay / eBird 图片 | 使用条款需核查 |
| GBIF / iNat / Commons | 各自许可不同 |
| 自建 manifest | 可发布,但不应包含不可再分发原图 |
| 训练后模型 | 是否可公开发布需按数据源条款确认 |
如果项目要正式开源,建议只发布:
- 训练代码
- taxonomy / class map
- 不含原图的 manifest
- 可复现下载脚本
- 每个来源的 license 说明
- 模型权重的单独许可说明
不要把“训练时能访问图片”和“可以把图片或训练产物随 GPL 项目发布”混为一谈。
八、发布前清单
前面几篇里分散出现的“还需要评估”,最后应该收成一张发布前清单:
| 类别 | 必查项 | 当前状态 |
|---|---|---|
| 数据与合规 | 逐来源 license / terms,manifest 不含原图,可按来源删除重训 | 部分梳理,发布前需复核 |
| 真实使用 | 凑 200-500 张真实用户上传风格照片,单独报告 top-1 / top-5 / reject | 未做 |
| 分类指标 | overall top-1、macro、tail bucket、per-source accuracy、相似种混淆对 | 部分已有,v4 主跑未完成 |
| LoRA 复盘 | LoRA vs frozen 的 per-class delta,头部/尾部类分别提升多少 | 未做 |
| 拒识指标 | false accept、false reject、reject score 灰区、不同拒识原因的 UI 文案 | AUC 已有,阈值和 UI 未定 |
| 部署指标 | 首启动延迟、单图延迟、内存峰值、MPS/CUDA/CPU 路径 | 单图核心延迟已有,首启动/内存未测 |
| 包大小权衡 | 8-head vs 4-head vs LoRA single 的精度、延迟、包大小 | 只有估算,需实测 |
| 置信度策略 | top-1 概率、top-1/top-2 margin、reject score、ensemble disagreement 的组合规则 | 未定 |
其中真实用户照片基准最关键。测试集上的 reject AUC = 0.92 只能说明它在当前数据分布上能区分一部分坏图;如果真实上传图里有大量远景、背影、遮挡、拍屏和相册截图,这个 AUC 的意义会明显变化。
小结
一个模型能不能上线,不只取决于 test top-1。对鸟类识别来说,bbox 裁切、拒识、延迟、包大小、设备兼容、数据许可,都会直接决定它是不是一个可用产品。
如果说训练篇解决的是“模型能不能识别”,部署篇解决的就是“它能不能可靠地替用户做判断”。这两件事相关,但不是一件事。下一步最该补的不是新模型名,而是真实用户照片基准、拒识阈值标定和发布许可核查。
wlfcss原创,转载请注明来源

![[鉴翎]中国鸟种识别模型训练-02模型训练](https://images.unsplash.com/photo-1713970294217-88b5a7084ec3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fGNoaW5hJTIwYmlyZHxlbnwwfHx8fDE3Nzc4MjMxNjB8MA&ixlib=rb-4.1.0&q=80&w=1140)